



Механизм полнотекстового поиска
Основные возможности полнотекстового поиска
- поддержка транслитерации (написание русских слов символами латиницы в соответствии с ГОСТ);
- поддержка замещения (написание части символов в русских словах одноклавишными латинскими символами);
- возможность нечеткого поиска (буквы в найденных словах могут отличаться) с указанием порога нечеткости;
- возможность указания области выполнения поиска по выбранным объектам метаданных;
- представление результатов поиска в формате XML и HTML с выделением найденных слов;
- полнотекстовое индексирование названий стандартных полей ("Код", "Наименование" и т.д.) на всех языках конфигурации;
- выполнение поиска с учетом синонимов русского, английского и украинского языков;
- морфологический словарь русского языка содержит ряд специфических слов, относящихся к областям деятельности, автоматизируемым с помощью системы программ 1С:Предприятие;
- возможность использования дополнительных словарей полнотекстового поиска;
- в состав поставляемых словарей включены словарные базы и словари тезауруса и синонимов русского, украинского и английского языков, предоставленные компанией "Информатик".
Полнотекстовый поиск в базе данных
Механизм полнотекстового поиска в данных системы 1С:Предприятие 8 позволяет осуществлять поиск в базе данных с указанием поисковых операторов (И, ИЛИ, НЕ, РЯДОМ и др.).
Механизм полнотекстового поиска основан на использовании двух составляющих:
- полнотекстового индекса, который создается для текущей базы данных и затем периодически, по мере необходимости, обновляется;
- средств выполнения полнотекстового поиска.
Создание и обновление полнотекстового индекса может быть выполнено интерактивно, в режиме 1С:Предприятие 8, или программно, средствами встроенного языка. Ниже приведен диалог управления полнотекстовым индексированием в режиме 1С:Предприятие:
Для выполнения поиска данных в базе данных может использоваться, например, обработка Поиск данных, представленная ниже.
В представленном примере найдены документы, реквизиты которых содержат значения, начинающиеся на "Компл" и "вент" - контрагент "Комплетк ТД" и реквизиты, содержащие различные формы слова "вентилятор".
Система 1С:Предприятие 8 позволяет осуществлять выборочное включение данных прикладных объектов и их реквизитов в полнотекстовый поиск. Также существует возможность ограничить область поиска данными только указанных объектов конфигурации.
Полнотекстовый поиск в справочной системе
В справочной системе 1С:Предприятия 8 также реализован полнотекстовый поиск, позволяющий использовать поисковые операторы И, ИЛИ, НЕ, РЯДОМ и др.. При этом найденные слова выделяются.
Программный интерфейс
Используются следующие прикладные объекты:
- МенеджерПолнотекстовогоПоиска
- СписокПолнотекстовогоПоиска
- ЭлементСпискаПолнотекстовогоПоиска
МенеджерПолнотекстовогоПоиска имеет методы для построения индекса поиска, проверки его актуальности, а также создания списка поиска типа СписокПолнотекстовогоПоиска по заданному запросу.
МенеджерПолнотекстовогоПоиска доступен как свойство глобального контекста ПолнотекстовыйПоиск.
СписокПолнотекстовогоПоиска предоставляет доступ к результатам поиска. Кроме того, можно указать область поиска в виде массива элементов метаданных конфигурации.
Результатом поиска является ЭлементСпискаПолнотекстовогоПоиска.
Операторы строки поиска
В строке ввода допускается использование следующих поисковых операторов:
И (AND или #) - поиск данных, содержащих все слова; пример: "запись И документ" - в реквизитах должны быть и "проведение" и "документ" (с учетом морфологии);
ИЛИ (OR или | или,) - поиск хотя бы одного слова из перечисленных; пример: "запись ИЛИ документ" - в реквизитах должно быть хотя бы одно из слов "запись" или "документ";
НЕ (NOT или ~) - поиск данных, в реквизитах которых есть первое слово, но нет второго; пример: "закрытие НЕ месяц" - будут найдены все, содержащие "закрытие", но не содержащие слова "месяц". Использование "~" в начале строки не допускается;
РЯДОМ/n (NEAR/[+/-]n) - поиск данных, содержащих в одном реквизите указанные слова с учетом морфологии на расстоянии n слов между словами.
Знак указывает, в каком направлении от первого слова будет искаться второе слово ("+" – после первого; "-" – до первого слова).
Если знак не указан, то будет найдены данные, содержащие указанные слова на дистанции n слов друг о друга.
Порядок слов не имеет значения.
- "фен РЯДОМ/3 воздух" - будут найдены данные, в которых "воздух" находится не более 3-х слов до или после "фен";
- фен РЯДОМ/+3 воздух - будут найдены данные, в которых "воздух" находится не более 3-х слов после "фен";
- фен РЯДОМ/-3 воздух - будут найдены данные, в которых "воздух" находится не более 3-х слов перед "фен".
РЯДОМ(NEAR) - упрощенный оператор дистанции: оба слова расположены не далее, чем в 8-ми словах друг от друга; пример: "проведение РЯДОМ документ";
"" (текст в кавычках) - поиск точной с учетом морфологии фразы, пример: "проведение документа" - эквивалентно: проведение /1 документа;
() - группировка слов (сколько угодно уровней вложенности); пример: "(проведение | выписка) # (счета, документа)";
* - поиск с использованием группового символа (замена окончания слова). Должно быть введено более 1 значащего символа; пример: "доку*" - найдет "документ", "документировать", "документальный" и др.;
# - нечеткий поиск слов с заданным количеством отличий от указанного (если не указано, то = 1); пример: запрос "#Система" найдет "систама", "сивтема"; запрос "Система#2" найдет "ситтама", "сеттема";
Поиск с учетом синонимов русского, английского и украинского языков. "!" ставится перед соответствующим словом; пример: поиск "!красный кафель", найдет еще и "алый кафель" и "коралловый кафель".
Если не указано никаких операторов (слова набраны через пробел), то программа осуществляет поиск всех слов из запроса с использованием оператора И.
Примеры
МассивМД = Новый Массив(); МассивМД.Добавить(Метаданные.Справочники.Товары); МассивМД.Добавить(Метаданные.Документы.КассовыйЧек);
СписокПоиска.ОбластьПоиска = МассивМД; СписокПоиска.СтрокаПоиска = ПолеВводаПоиска; СписокПоиска.РазмерПорции = РазмерПорции; СписокПоиска.ПерваяЧасть();
Если СписокПоиска.ПолноеКоличество() = 0 Тогда Если СписокПоиска.СлишкомМногоРезультатов() Тогда Предупреждение("Слишком много результатов, уточните запрос."); КонецЕсли; Возврат; КонецЕсли;
Колво = СписокПоиска.ПолноеКоличество();
СтрHTML = СписокПоиска.ПолучитьОтображение(ВидОтображенияПолнотекстовогоПоиска.HTMLТекст); Сообщить(СтрHTML);
Для каждого индекс=0 По СписокПоиска.Количество-1 Цикл элемент = СписокПоиска.Получить(индекс); Сообщить(элемент.Представление); КонецЦикла;
Особенности
Полнотекстовый поиск работает по всему массиву данных, поэтому при использовании надо обязательно пропускать результат через фильтр безопасности.
Например, в мультибазной системе нужно отсекать объекты других баз.
Кроме того, такая фильтрация тесно пересекается с контролем доступа. Известно, что очень часто "дырой" в безопасности являются как раз механизмы поиска.
Функциональность нового поиска основана на двух механизмах:
- полнотекстовый поиск (работает очень быстро и требует минимум вычислительных ресурсов);
- поиск средствами СУБД (в общем случае длительность поиска и затраты вычислительных ресурсов пропорциональны объему информации в таблице).
В текущей реализации поиск в списке будет осуществляться без использования
полнотекстового поиска в следующих случаях ():
- полнотекстовый индекс выключен на уровне информационной базы;
- объект основной таблицы не индексируется полнотекстовым индексом;
- в результате поиска с помощью полнотекстового поиска, была получена ошибка.
Если же полнотекстовый поиск включен в информационной базе, а индекс не обновлен совсем или частично (из моей практики 95% информационных баз Заказчиков), то пользователь при поиске получит либо недостоверный, либо пустой результат поиска.
Спрашиваем у Фирмы 1С - как быть? как гарантировать достоверность результатов поиска всегда?
Получаем ответ: Да, для того, чтобы результаты поиска при включенном полнотекстовом поиске были актуальными, нужно следить за тем, чтобы индекс полнотекстового поиска был актуальным.Других вариантов эффективного и актуального поиска пока нет
().
А существует ли вообще "актуальный полнотекстовый индекс"? Зависит от числа пользователей, интенсивности изменения информации в базе и частоты запуска обновления индекса. Обычно обновление индекса запускают раз в 60 секунд. Хорошо, если объектов было изменено не много, и процедура успела обработать все изменения за эти 60 секунд. А если сделали перепроведение группы документов, или массовую перезапись справочника? В этом случае никто не может гарантировать время, через которое поиск по индексу снова даст достоверные данные.
В принципе, это не особо критично, кроме нескольких ситуаций. Частый вариант работы пользователей - установить в списке отбор по какому-то значению, например "Контрагенту", ввести новый или скопировать существующий документ и записать. Со старым поиском новый документ моментально был виден в списке. Теперь пользователь его увидит только через N секунд в лучшем случае, где N скорее ближе к 50-60 секундам, нежели к 2-3.
Если не заметить, что нового документа нет и по отобранным результатам предоставить информацию кому-либо, то она будет заведомо недостоверной.
Это было в случае нормальной работы с информационной базой. А что будет в специфических ситуациях? Приведу пару примеров.
1) В рабочей базе полнотекстовый индекс включен и часто обновляется. Пользователь просит развернуть ему копию рабочей базы, что по ней заняться анализом данных.
Восстанавливаем бэкап и даем доступ. Вот только полнотекстовый поиск работать не будет, т.к. индекс хранится не в СУБД, а в отдельных файлах (и в файловом, и в клиент-серверном варианте). Индекса нет в dt-файле.
т.е. чтобы пользователь смог использовать поиск по спискам - надо выключить полнотекстовый индекс в этой базе. Правда пользователь будет слегка удивлен тому, что поиск будет выполняться гораздо дольше. Либо перестроить индекс по всей базе.
2) (Актуально для более менее больших баз). В рабочей базе полнотекстовый индекс включен и часто обновляется. Наступает конец месяца и начинается закрытие периода. Начинаем массово грузить и перепроводить документы. Для снижения нагрузки на систему блокируем выполнение регламентных заданий, соответственно, и обновление индекс останавливается. Пользователи будут, мягко говоря, в недоумении - чего же в списках нет новых или измененных документов. Единственный выход - отключить полнотекстовый поиск для информационной базы, и, соответственно, получить еще большую нагрузку на оборудование за счет тяжелого поиска по всем реквизитам.
Таким образом, как мне кажется, операция по обновлению индекса станет еще одной головной болью администраторов информационных баз.
Система, ранее гарантировавшая 100% достоверность и актуальность информации в любой момент, сейчас превращается скорее в справочную систему, в которой нельзя быть полностью уверенным.
А пользователи получают еще один повод для упрека ИТ-шников - "ваша система неправильно работает".
Многие СУБД поддерживают методы полнотекстового поиска (Fulltext search), которые позволяют очень быстро находить нужную информацию в больших объемах текста.
В отличие от оператора LIKE, такой тип поиска предусматривает создание соответствующего полнотекстового индекса, который представляет собой своеобразный словарь упоминаний слов в полях. Под словом обычно понимается совокупность из не менее 3-х не пробельных символов (но это может быть изменено). В зависимости от данных словаря может быть вычислена релевантность – сравнительная мера соответствия запроса найденной информации.
В статье рассказывается как работать с полнотекстовым поиском на примере БД MySQL, а так же приведу примеры «нестандартного» использования данного механизма.
В MySQL возможности полнотекстового поиска (только для MyISAM-таблиц) поддерживаются начиная с версии 3.23.23. В последующих версиях механизм потерпел существенные доработки и расширения, в тоге превратившись в мощное средство для создания поисковых механизмов веб-приложений. Главная особенность – быстрый поиск слов в очень больших объемах текстовой информации.
Индекс FULLTEXT
Итак, чтобы работать с полнотекстовым поиском, сначала нам нужно создать соответствующий индекс. Он называется FULLTEXT , и может быть наложен на поля CHAR, VARCHAR и TEXT. Причем, как и в случае с обычным индексом – если происходит поиск по 2-м полям, то нужен объединенный индекс 2-х полей, используйте поиск по одному полю – нужен индекс только этого поля. Например:CREATE TABLE `articles` (
`id` int(10) unsigned NOT NULL auto_increment,
`title` varchar(200) default NULL,
`body` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `ft1` (`title`,`body`),
FULLTEXT KEY `ft2` (`body`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
В этом примере создается таблица с 2-мя полнотекстовыми индексами: ft1 и ft2 , которые можно использовать для поиска в полях title и body , или только в body . Только в поле title искать не получится.
Конструкция MATCH-AGAINST
Собственно для самого полнотекстового поиска в MySQL используется конструкция MATCH(filelds)… AGAINST(words) . Она может работать в различных режимах, которые достаточно сильно между собой отличаются. Для всех действует следующее правило: данная конструкция возвращает условную релевантность, но способ вычисления которой может быть разным в зависимости от режима. Еще стоит добавить что во всех режимах поиск всегда регистрозависимый. Далее более подробно о каждом из них.MATCH-AGAINST IN NATURAL LANGUAGE MODE
- это основной вид поиска, который используется по умолчанию, т.е. если режим не указан:SELECT * FROM `articles` WHERE MATCH (title,body) AGAINST ("database");
В этом примере мы ищем слово database в полях title и body таблицы articles на основе индекса ft1 (см. пример создания таблицы выше). Выборка будет автоматически отсортирована по релевантности – это происходит в случае указания конструкции MATCH-AGAINST внутри блока WHERE и не задано условие сортировки ORDER BY.
Кстати, несмотря на возможности алиасов, при запросах конструкцию приходится повторять в разных местах, что усложняет запросы. Вот например нельзя написать так:
FROM `articles`
WHERE REL > 0;
Этот запрос выдаст ошибку: поле Rel не определено . Что бы работало, придется продублировать данную конструкцию:
SELECT *, MATCH (title,body) AGAINST ("database") as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST ("database") > 0;
Однако, сколько бы вы не использовали одну и туже конструкцию (разумеется с одинаковыми параметрами) она будет вычислена только один раз .
В примере выше в переменной REL будет вычислена релевантность. Эта величина зависит прежде всего от количества слов в полях tilte и body , того насколько близко данное слово встречается к началу текста, отношения количества встретившихся слов к количеству всех слов в поле и др.
Например, релевантность будет не нулевая, если слово database встретится либо в title , либо body , но если оно встретится и там и там, значение релевантности будет выше, нежели если оно два раза встретится в body .
Сама по себе релевантность ничего не определяет. Это лишь сравнительная характеристика, по которой можно сортировать результат выборки, не более того.
Еще следует заметить что для IN NATURAL LANGUAGE MODE действует так называемое «50% threshold» . Это означает, что если слово встречается более чем в 50% всех просматриваемых полей, то оно не будет учитываться, и поиск по этому слову не даст результатов.
MATCH-AGAINST IN BOOLEAN MODE
В бинарном режиме, в отличие от других режимов, релевантность вычисляется несколько иначе - как условная мера совпадения заданного шаблона. Положение искомого шаблона в тексте, количество встретившихся вариантов роли не играют.Самая важная особенность бинарного режима – возможность указания логических операторов . Сами операторы я приводить не буду, о них хорошо рассказано в оригинальной документации по MySQL .
Еще особенностями бинарного режима является отсутствие автоматической сортировки в случае указания условия WHERE, однако для сортировки можно использовать алиас:
SELECT *,
MATCH (title,body) AGAINST ("+database MySQL" IN BOOLEAN MODE) as REL
FROM `articles`
WHERE MATCH (title,body) AGAINST ("+database MySQL" IN BOOLEAN MODE)
ORDER BY REL;
Пример выведет все записи содержащие слово database , но если в записи присутствует слово MySQL , то его релевантность будет выше. Записи будут отсортированы по релевантности.
В бинарном режиме отсутствует ограничение «50% threshold» . Бинарный режим можно использовать и без создания полнотекстового индекса, однако это будет работать очень медленно.
MATCH-AGAINST IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION
Или просто «WITH QUERY EXPANSION» . Работает примерно также, как NATURAL LANGUAGE MODE, с той лишь разницей, то в результат поиска попадают не только совпадения с шаблоном, но и возможные логические совпадения. Это работает примерно так:Сначала MySQL выполняет запрос аналогичный NATURAL LANGUAGE MODE и формирует результат. По этому результату производится попытка вычислить слова, которые так же имеют высокую релевантность для полученной выборки. В случае, если эти слова присутствуют производится поиск и по ним тоже, но значение их на релевантность будет существенно ниже. Отдается смешанная выборка – сначала те результаты, где слово присутствует, а потом те, которые были получены в результате «повторного» поиска.
Использование FULLTEXT SEARCH
Пара слов об алгоритмах поиска
Ну, конечно полнотекстовый поиск можно использовать прежде всего для написания алгоритмов поиска. :-) Я не буду заострять на них внимание, скажу просто что при индексации текстовой информации может понадобиться сложный алгоритм обработки, например такой:- убрать все HTML-теги
- убрать все непечатные символы, знаки препинания и тому подобное
- убрать все слова длинной менее 3-х символов
- перевести все слова в нижний регистр
Соответственно, с поисковым запросом надо сделать тоже самое. Режим поиска используется любой – как удобнее… А вообще поиск – это отдельная тема, про которую нужна отдельная статья.
Раскрытие связок многое-ко-многим
В некоторых случаях – не во всех – с помощью полнотекстового поиска можно раскрывать соотношения многое-ко-многим без привлечения третьей таблицы.Допустим, у нас есть две большие таблицы: с пользователями и группами пользователей . Причем, каждый пользователь имеет отношение к большому количеству различных групп, в свою очередь группы включают в себя большое количество пользователей. При нормальном соотношении (т.е. раскрытии через 3-ю таблицу), что бы выбрать все группы, которые принадлежат к некоторому пользователю понадобиться сделать запрос, объединяющий 2 или 3 таблицы, что даже при присутствии индексов очень накладно.
Однако можно выполнить денормализацию по следующей схеме:
Теперь, что бы выбрать группы, принадлежащие к пользователю 2 можно сделать:
SELECT *
FROM `groups`
WHERE MATCH (groups) AGAINST ("+user2" IN BOOLEAN MODE);
Это будет работать намного быстрее, чем исходный вариант (с 3-ей таблицей). Аналогично с группами, но если подобные выборки нам в принципе не нужны, то можно обойтись без соответствующего поля в таблице групп. Тогда получится что-то вроде «односторонней» связи M:N. То есть можно вычислить все M, которые принадлежат к N, не нельзя сделать обратного.
В этом случае, как правило, используется IN BOOLEAN MODE.
- Кстати, на эту схему очень хорошо ложится тегирование информации, но там не все так просто и это опять же отдельная тема.
Использование релевантности как меры отношения одного объекта к другому
Один из алгоритмов для вычисления статей, «похожих» на данную статью . Всё просто: берутся теги данной статьи, и делается полнотекстовый запрос по полю с тегами всех остальных статей с сортировкой по релевантности (если она нужна). Естественно, сначала вылезут те, которые содержат максимальное совпадение по тегам.Можно и без учета тегов. Если статьи индексированы для полнотекстового поиска, из индекса выбираются с десяток наиболее употребляемых слов, после чего делается поиск по ним.
Или вот еще пример – интересы пользователей. Используя точно такую же схему можно легко найти других пользователей, у которых интересы наиболее соответствуют вашим.
И кое-что в заключение:
Несмотря на все возможности полнотекстовых индексов, стоит учитывать, что сами индексы занимают очень значительное место на диске, и изменения таблиц с ними будет выполняться значительно дольше.Совет1: Отключить полнотекстовый поиск*
Большинство бухгалтеров не знают о существовании данной функции и никогда ею не пользуются (Сервис - Поиск данных)
Механизм полнотекстового поиска в 1С позволяет находить информацию в 1С по ключевым словам (по аналогии с поиском в интернете, когда вы вводите слово, и вам выдаются результаты запросов). При этом время поиска существенно зависит от объемов базы и может занимать несколько часов. Отключение механизма полнотекстового поиска не влияет на другие функции и стабильность работы в 1С.
Механизм полнотекстового поиска в 1С по умолчанию включен. Чтобы отключить полнотекстовый поиск, нужно зайти Операции - Управление полнотекстовым поиском -Настройка и убрать признак «Разрешить полнотекстовый поиск »
Отключение механизма полнотекстового поиска осуществляется в монопольном режиме (никто не должен работать в программе, кроме вас)**
Отключение механизма полнотекстового поиска дает увеличение производительности до 10%.
Совет2: Пересчет итогов*
Большинство бухгалтеров не знают о существовании данной операции, а ее необходимо выполнять каждый месяц.
Итоги - это механизмы 1С для быстрого доступа к данным при формировании отчетов и выполнении различных вычислительных операций.
Для того, чтобы выполнить пересчет итогов требуется зайти в Операции - Управление итогами, установить дату по которую рассчитать итоги (начало текущего месяца) у раздела «Все регистры» и нажать кнопку «Выполнить»
Пересчет итогов осуществляется в монопольном режиме (никто не должен работать в программе, кроме вас)**
Пересчет итогов дает увеличение производительности до 10%.
Совет3: Отключить версионирование объектов***
Большинство бухгалтеров не знают о существовании данной функции и не используют ее.
В отличие от стандартного журнала регистрации версионирование объектов позволят хранить информацию не только о том, какой пользователь работал с документом, но и что именно он изменил (Сервис - История изменения объектов). Данный режим бывает полезен, но рекомендуется включать его только для определенного списка документов, т.к. он ведет к снижению производительности 1С и росту информационной базы
Настройка версионирования осуществляется через Операции - Настройки программы -Версионирование. Если настройка не требуется, то нужно убрать признак «Использовать версионирование объектов».
Если настройка нужна для определенного перечня документов, то зайти в «Настройку версионирования объектов» и правой кнопкой мышки установить настройку «Версионировать» для нужных объектов**
Отключение версионирования дает увеличение производительности до 5%.
_________________________________________________________________
*Для конфигураций на базе «1С:Управление Производственным предприятием», «1С:Комплексная автоматизация», «1С: Бухгалтерия предприятия 2.0», «1С:Управление Торговлей 10.3»
**Перед выполнением регламентных операций с базой обязательно создание копии базы.
***Для конфигураций на базе «1С:Управление Производственным предприятием», «1С:Комплексная автоматизация».
Механизм полнотекстового поиска в 1С позволяет быстро находить необходимую для пользователя информацию. Данный вид поиска особенно эффективен, если информационная база располагает большим объемом информации, а также точно не известно, где находятся интересующие пользователя данные или как часто бывает, их точное название не известно. Для того чтобы открыть окно управления полнотекстовым поиском необходимо выполнить следующее: пункт меню Операции Управление полнотекстовым поиском .
В данном окошке можно наблюдать три кнопки: Настройка - Включение/Отключение полнотекстового поиска;

Обновить индекс – Создание индекса/Обновление индекса; Очистить индекс – обнуление индекса(рекомендуется после обновления всех данных); пункт Разрешить слияние индексов – отвечает за слияние основного и дополнительного индекса.
Полнотекстовый поиск осуществляется при помощи полнотекстового индекса. При отсутствии индекса полнотекстовый поиск как таковой не возможен. Для того чтобы поиск имел результат, все необходимые данные должны быть включены в полнотекстовый индекс. Если пользователем введены в базу новые данные, их следует включить в рассматриваемый индекс, иначе они не будут участвовать в поиске. Чтобы этого избежать, необходимо обновлять полнотекстовый индекс. При обновлении система анализирует только определенные типы данных: Строка, Данные ссылочного типа (ссылки на документы, справочники),Число, Дата, ХранилищеЗначения . Если пользователь не имеет прав доступа к определенной информации, то он не сможет увидеть ее в результатах поиска. Следует также помнить и о том, что в свойствах объектов, по которым будет происходить поиск должно быть установлено значение Полнотекстовый Поиск – Использовать , которое задано по умолчанию.

Как вы можете заметить свойство Использовать установлено для всего справочника РегНомера , но сделать это можно и для каждого его реквизита соответствующего типа.
Рассмотрим более подробно полнотекстовый индекс, который состоит из двух частей (индексов): основного индекса и дополнительного . Высокая скорость поиска данных обеспечивается за счет основного индекса, но обновление его происходит относительно медленно, в зависимости от объема данных. Дополнительный индекс ему противоположен. Данные добавляются в него намного быстрее, но поиск осуществляется медленнее. Система осуществляет поиск одновременно в обоих индексах. Большая часть данных находится в основном индексе, а данные добавляемые в систему попадают в дополнительный индекс. Пока объем данных в дополнительном индексе небольшой, поиск по нему происходит относительно быстро. В тот момент, когда нагрузка на систему невелика, происходит операция слияния индексов, в результате чего дополнительный индекс очищается, а все данные помещаются в основной индекс. Слияние индексов предпочтительнее выполнять в тот момент времени, когда нагрузка на систему минимальна. С этой целью можно создавать регламентированные задания и задания по расписанию.
Рассмотрим случай автоматического обновления индекса при запуске приложения. Данный случай подходит для однопользовательских баз данных (в качестве однопользовательских баз данных могут выступать такие продукты как 1С Бухгалтерия Базовая, 1С Упрощенка ), так как при большом количестве пользователей обновление будет происходить после запуска приложения каждого из пользователей, что в результате очень сильно скажется на производительности системы.
Для начала создадим общий модуль и назовем его, к примеру ПП. В нем пропишем следующую процедуру:
Процедура ОбновлениеИндексы() Экспорт
ПолнотекстовыйПоиск.ОбновитьИндекс();
КонецПроцедуры
Так же установим свойства как на рисунке.

Затем щелкнем правой кнопкой мыши на названии конфигурации в дереве конфигурации и выполним команду Открыть модуль управляемого приложения. Выберем в маленьком окошке сверху предопределенную функцию ПередНачаломРаботыСистемы и поместим в эту процедуру следующую строчку:
ОбновлениеПолнотекстовогоПоиска.ОбновлениеИндексы ();

Сохраняем внесенные изменения. Таким образом, после каждого запуска приложения индекс будет обновляться автоматически.
Теперь рассмотрим случай, когда пользователей несколько. Здесь воспользуемся Регламентными Заданиями (в режиме Конфигуратор: в дереве конфигурации – Общие – Регламентные Задания). В данном случае нас интересуют только два задания: ОбновлениеИндексаПолнотекстовогоПоиска и СлияниеИндексаПолнотекстовогоПоиска. В свойствах этих заданий выберем Расписание и нажмем на сслыку Открыть.

Настраиваем расписания у обоих заданий. Рекомендаций по настройке в данном случае нет, здесь настройка определяется исходя из особенностей работы системы (нагрузки, объема информации, частоты ее обновлениея т.д.). Сами по себе задания работать не будут, нам потребуется иметь запущенный сеанс программы в режиме Предприятия , который и будет отвечать за выполнение этих заданий. Сразу следует заметить, что данный вариант работы используется для файловой системы. В этом сеансе должна быть запущена обработка ожидания, выполняющая вызов метода встроенного языка. Данная обработка будет иметь следующий вид:

Перейдем в режим Предприятия и выполним следующее: Запустим нашу обработку, которая в данном случае будет вызываться каждые 5 секунд и, в свою очередь вызывает метод “ВыполнитьОбработкуЗаданий()”. Данный метод проверяет настало ли время выполнять задания согласно их расписанию. Далее перейдем в пункт меню Операции – Константы – Настройка программы – вкладка Обмен Данными.

Определим пользовательский сеанс, который будет отвечать за выполнение и установим интервал опроса регламентных заданий. Работать в данном сеансе не рекомендуется, так как это может сказаться на производительности системы. Также на дисках ИТС имеется обработка “ЗапускРегламентныхЗаданий ”, которая принудительно запускает регламентные задания по выбору пользователя. Форма данной обработки выглядит следующим образом:

Таким образом все подготовительные работы выполнены и можно приступать непосредственно к самому поиску данных.
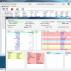
Чтобы начать работать с полнотекстовым поиском необходимо выполнить следующую команду: меню Сервис à Поиск данных .
После чего появится следующее окно:

Нажав на кнопку Настройки , появится поле с дополнительными настройками, такими как: Ограничение области поиска , Нечеткость , Размер Порции (в данном случае значение = 5, что означает вывод по пять результатов поиска на страницу). Параметр Нечеткость обозначает несовпадение части символов в поисковом запросе и полученной в ходе поиска информации. Нечеткость задается в процентном соотношении.
Полнотекстовый поиск может использовать следующие операторы:

Помимо этого механизм полнотекстового поиска допускает написание части символов русского слова одноклавишными латинскими символами. Результат поиска при этом не измениться.
В клиент-серверном варианте планированием выполнения заданий занимается планировщик заданий.
Планировщик заданий является активным компонентом сервера, т.е. независимо от наличия клиентских соединений с сервером он может выполнять регламентные задания. Активность планировщика особенно заметна, когда он последовательно опрашивает все информационные базы на предмет наличия в них регламентных заданий. Планировщик может отложить опрос определенной информационной базы, если на информационную базу наложена блокировка соединения или блокировка регламентных заданий.
Текущий список регламентных заданий в планировщике может автоматически изменяться (например, когда создается новое или удаляется уже существующее регламентное задание). В любом случае механизм заданий обеспечивает актуальность списка регламентных заданий планировщика и его соответствие спискам регламентных заданий информационных баз кластера.
После того как начальный список регламентных заданий успешно получен, планировщик периодически проверяет, не поступили ли запросы на выполнение фоновых заданий и не нужно ли выполнить какие-либо регламентные задания в соответствии с их расписанием. После того как задание получено рабочим процессом, рабочий процесс устанавливает соединение с информационной базой и выполняет задание в рамках этого соединения. Поскольку рабочий процесс оптимизирован для многопользовательской работы, только первое создание соединения с информационной базой является затратной операцией. Установка последующих соединений с той же информационной базой занимает существенно меньше времени и ресурсов, т.к. большинство внутренних структур данных разделяются между соединениями одной информационной базы. После выполнения задания рабочий процесс уведомляет планировщика об успешном или неуспешном выполнении задания. В случае программного сбоя планировщик может перезапустить регламентное задание (если сбой произошел при выполнении фонового задания, то оно не будет перезапущено).
Спасибо!
Вам также будет интересно:

В ходе проведения реформирования системы образования, в настоящее время большое внимание...

На этой неделе прошел семинар компании Philips под названием "Новинки и сенсации мира...

Скорость шины системной платы не влияет на скорость установленного процессора. В...

Представляем вам уникальную карту, с помощью которой можно обнаружить местоположение любого...
World of Tanks - уникальная PvP-игра, в которой ежедневно проходят десятки тысяч сражений,...

